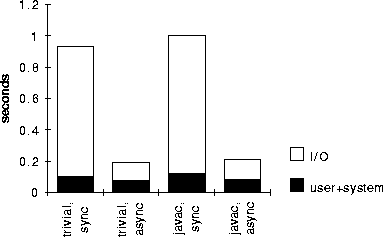
Figure 2: Checkpointer delay is reduced by deferring disk writes.
Several techniques have been proposed for adding persistence to the Java language environment. This paper describes a system we call icee that works by checkpointing the Java Virtual Machine. We compare the scheme to other persistent Java techniques. Checkpointing offers two unique advantages: first, the implementation is independent of the JVM implementation, and therefore survives JVM updates; second, because checkpointing saves and restores execution state, even threads become persistent entities.
Previous papers at this workshop have outlined a variety of strategies for providing persistence for Java programs. We needed persistence for Java objects, and none of the systems we reviewed seemed suitable for our purposes. One important requirement was persistent threads. To make this a simple project, a second requirement was that the implementation did not involve modifying the Java Virtual Machine.
We first discuss the semantics provided by our checkpointer, and then look at its functionality, implementation and performance. We propose future work, and then provide an overview of related persistent Java systems and checkpointing systems.
Our system provides persistence by checkpointing a running JVM process. This technique gives rise to a unique set of persistence semantics. Moss and Hosking provide a taxonomy for categorizing persistent systems [MH96]. Figure 1 characterizes our checkpointer according to their taxonomy, to put it into the context of the persistent Java literature.
|
|
The following semantic consequences arise from our checkpointing persistence scheme:
Of greater interest to us are communications links. We do not aim to provide a distributed checkpointing system, so we cannot roll back the state of remote entities, nor can we, in general, even transparently reopen closed links to the remote entity. Therefore, the only alternative is to let the link appear forcefully closed to the persistent process. Applications that handle unexpectedly closed connections should be able to reestablish communications with their remote counterparts. Some applications will share state across virtual machines, so restoring one machine to a previous point would produce an inconsistent state. We presume that such distributed applications will need to provide their own support (possibly by explicitly controlling our single-process checkpointing mechanism) for distributed consistency.
Most systems that save the class definitions with the persistent data face the same class-evolution problem, so a solution suitable for other systems may be applicable to ours.
The data in a checkpointed JVM is limited by the size and performance of virtual memory on the host operating system. On 32-bit systems, often only one or two gigabytes of virtual address space is available for user data. To relieve the size restriction, our system would need to run on a machine with a 64-bit pointer size, and we would need access to a user-level mechanism for backing memory pages with user-allocated files rather than the system-allocated swap partition.
We next outline the procedure used to establish checkpoints and to recover from failures, represented graphically in Figure 6. We also show the user and programmer interfaces to the system.
% java myprog args becomes % icee myprog argsThe java program may explicitly call Checkpoint.Control.doCheckpoint() to establish a checkpoint. Alternatively, icee can be invoked using a wrapper class, Checkpoint.Auto, that provides periodic checkpointing and a callback interface to notify interested objects when a recovery has taken place. The command
% icee Checkpoint.Auto -period=60 myprog argsexecutes myprog(args), taking a checkpoint every 60 seconds.
% icee -recoverThis is implemented as follows:
It turns out that /proc fails to mention reserved pages that are mapped but unallocated.1 These pages are used by thread stacks, and appear, zero-filled, as soon as they are accessed. We interpose on all mmap calls to acquire this information.
The green_threads package used to implement the JVM overrides many symbol names from libc to provide alternative implementations of system functions such as open, read, and dup. Our checkpointer, which is meant to be built as a layer below the entire JVM, must be careful to access the system services directly.
Furthermore, we interpose on some system calls to collect information that is not available at checkpoint time from /proc. Currently, that means we have to provide a specially-linked javai substitute, a simple program that calls the Java Native Interface. We would prefer to have a native class checkpointer that loads entirely from a shared library, but by that point in the process' life, we have missed the opportunity to interpose on library calls.2
The green_threads package also makes ioctl calls on file descriptors to arrange for nonblocking behavior and to request signals to indicate when the descriptors are ready to be accessed. This process state is hidden in the kernel, not in the process memory map, so we must be careful to save and restore it explicitly, lest green_threads become confused at recovery time.
Because we cannot restore open socket connections, we need a clean way to persuade the JVM (in particular, green_threads) that the socket has spontaneously closed. To accomplish this, we restore the application with dead sockets attached to the file descriptors associated with sockets in the checkpointed process.3 This technique works as desired for code using the java.net.Socket class, including RMI code. An obvious consequence is that the application program must be prepared to recover in a useful way from an exception delivered due to a lost socket connection.
The awt package seems to immediately call exit() upon discovery of an unexpectedly closed filehandle. We are looking into how we might fully deceive awt.
We have just described how the checkpointer is implemented. In this section, we examine the cost of taking checkpoints, and the overhead experienced during normal execution.
The results are presented in Figure 2. The total height of the bars is the wall-clock time, so the white sections represent time the application spends waiting for I/O. The maximum coefficient of variation was 0.08. The async values represent main-memory checkpointing, wherein we defer writing to disk until after the program is allowed to continue. In that case, the latency seen by the target program due to checkpointing is around 0.2 seconds.
|
Figure 2: Checkpointer delay is reduced by deferring disk writes. |
We expected overhead of checkpointing during normal execution to be low, since currently the only costs are the interposition on the open() and mmap() system calls. We measured this by invoking the Java compiler on a simple class five different ways. The results presented in Figure 3 are the user+sys times for one compilation of the simple class. We ran about forty trials of each case, in random order, on an unloaded system, with all jobs fitting in main memory. The maximum coefficient of variation was 0.06.
In the first case, javac, we directly invoked the Java compiler on the target class. For the remaining four cases, we wrote a wrapper class with a main() method that invokes sun.tools.javac.Main.compile(). The wrapper class allowed us to invoke the compiler from the normal Java interpreter (the java bar), and from our modified interpreter.
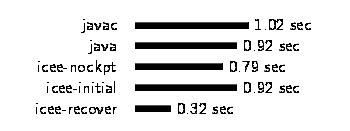
Figure 3: The checkpointer introduces negligible runtime overhead. |
The icee-nockpt bar represents invoking the wrapper with icee, but without taking a checkpoint. The icee-initial bar represents invoking the wrapper with icee, and taking a checkpoint before exiting. We are not certain why java and javac took so much longer to start up than icee-nockpt, which amounts to a simple Java Native Interface invocation, but it may be partly due to the shell scripts that wrap the javai and javac binaries.
The icee-recover bar represents restarting the checkpoint taken by icee-initial to invoke the compiler again. This case shows how taking a snapshot of the Java compiler after it has completed the CPU-intensive task of loading and verifying all of its classes dramatically shortens startup time for future compilations [Jor96]. The same concept has been applied in many contexts; Section 7.2.2 mentions some examples.
We have several ideas for improvements to our checkpointer. Plank's libckpt package includes two several common optimizations we would be silly to overlook [PBKL95]. We may exploit shared libraries to save time and disk space. We may simplify the tool by packaging it completely as a native class. We may provide a way for our data to persist beyond class and JVM upgrades. We may modify icee to allow the creation of persistent data repositories. And finally, we may port the system to other platforms.
Currently, recovery requires the checkpoint image and a copy of the original icee binary that generated it. We would like to make the checkpoint image files executable, so they are completely self-contained.
% icee RepositoryClass myprog myargsThe RepositoryClass would invoke myprog.main(myargs). Then RepositoryClass would force an immediate checkpoint and exit the JVM. To run another program against the repository, we would invoke:
% icee -recover myprog2 myargsThe recover operation would reawaken the original invocation of RepositoryClass, and inform it of the recovery so it does not merely exit again. The RepositoryClass would somehow acquire the new command-line arguments, and invoke myprog2.main(myargs).
Our checkpointer lies at the intersection of the persistent Java world and the checkpointing world. The first subsection categorizes persistent Java approaches according to the layer of software they modify. The second section examines previous uses of checkpointing.
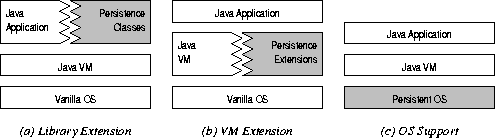
Figure 4: Existing proposals for Java persistence fall into three categories. |

Figure 5: Our checkpointer-based scheme inserts a layer between the Java VM and the operating system. |
Persistent Java maps Java objects to a database via JDBC. The system is implemented as a Java class library, and involves no changes to the compiler or the JVM [dST96]. Classes in Persistent Java must be declared persistent.
The Jspin system provides persistence through a mapping to an object-oriented database. Jspin also avoids modifying the JVM, but requires processing any potentially persistent classes through a modified compiler [RTW97, WKMR96].
The ObjectStore PSE system uses a bytecode postprocessor to insert residency and update checks into methods for potentially-persistent classes [O'B96, LLOW91].
Concordia, an infrastructure for mobile agents, employs Java serialization facilities to provide persistence for agent code and data [WPW+97].
The PJama project extends the JVM by adding a persistent object pool alongside the original transient object heap. Objects are moved out to a buffer pool of storage made persistent using the Recoverable Virtual Memory (RVM) package [Spe96, SA97, Jor96, ADJ+96, PAD+97].
Moss and Hosking describe a new Java interpreter that they expect to base on their Persistent Smalltalk system [MH96].
Transactions for Java extends the JVM to log changes to the heap, and back them to stable storage using RVM [GN96].
The Persistent Java project from IBM modifies a JVM to simulate a large address architecture, even on 32-bit hardware. That address space is made persistent by shared address space subsystem [Mal96, JMN+97].
A third approach to Java persistence is to run the JVM and Java application on top of a persistent operating system. See Figure 4(c). The advantage of such an approach is ubiquitous, orthogonal persistence without modification to the JVM. A drawback is compatibility: most end users do not have the freedom to replace their conventional operating system with a persistent one.
We are aware of only one proposal that would make threads persistent. Dearle et al. suggest implementing Java on top of the Grasshopper persistent operating system. They describe how Grasshopper could be used below a JVM (or other language) to provide transparent persistence support, without modifying the runtime language system at all [DHF96, Dea97, RDH+96].
Lee and Anderson provide a thorough introduction to fault tolerance; they cover checkpointing in chapter seven in the context of backward error recovery [LA90]. Cristian gives an overview of fault tolerance [Cri91]. He discusses how checkpointing and rollback provide failure masking for individual servers and server groups. Bowen and Pradhan discuss applications of checkpointing throughout the memory hierarchy [BP93]. The following two sections discuss extensions of checkpointing to distributed systems and some interesting uses of checkpointing.
Strom and Yemini wrote a seminal paper on distributed checkpointing using message logs to recover consistent states from asynchronous checkpoints [SY85]. Li, Naughton and Plank implemented a real-time, concurrent checkpointing system for parallel applications [LNP90].
Chiueh describes a hardware optimization for checkpointing [Chi93]. By preventing checkpoints from slowing down the target process, Chiueh's design enables a checkpoint-per-message approach to consistent distributed checkpoints, which is the most straightforward solution to the nondeterminism and cascaded rollback problems encountered in distributed checkpointing.
POGS is a checkpoint coordinator, a CORBA service that assists a distributed application in taking globally-consistent checkpoints [Zwe97].
Morin and Puaut discuss the application of checkpointing to distributed shared virtual memory systems [MP97]. DSVMs are an interesting design point for checkpointing because of their implicit communication patterns that differ from those of explicit message-based systems. ICARE, for example, is a checkpointed DSM that can improve execution time of an application because the pages replicated to form a checkpoint can serve as read-only replicas [KMB98].
Smith and Ioannidis implemented remote fork, a process migration system for Unix [SI88]. It works by checkpointing, transferring the checkpointed image to another machine, and restarting the image on the destination host. Their migrated processes are ``deaf and dumb;'' that is, they do not attempt to handle the disconnected file descriptors. The reader interested in process migration will find a number of useful citations in that paper.
Some languages such as Smalltalk and Self use snapshots as a way to save the state of the virtual machine and provide a persistent application programming environment. Emacs and TeX both dump core during their installation process, and postprocess the core file to produce a runnable image that saves some initial processing in future invocations. Perl makes the same dump/reincarnate functionality available to the programmer.
Checkpointing enables an intriguing mode of program debugging known as reverse execution. A sidebar in Bowen's overview describes this process [BP93].
By checkpointing a Java Virtual Machine, we provide persistence to the Java language environment. Our checkpointer offers a unique set of advantages: it provides type orthogonality, persistence by reachability, and thread persistence; it does not require modifying the JVM (or tracking changes to it); and it runs on a commodity operating system. It suffers some disadvantages: it is difficult to migrate persistent data to new JVMs or platforms; it is inefficient because all data is made persistent; and it does not offer support fine-grained transactions. Overall, it occupies an interesting and useful point in the space of persistent Java solutions.
The version of icee described in this paper is available at:
ftp://ftp.cs.dartmouth.edu/pub/jonh/icee-1.0.tgz
Thanks to my advisor David Kotz for guidance in the project and his always thoughtful comments on writing. Thanks to the anonymous reviewers for their thoughtful suggestions. Thanks also to Sun Microsystems for providing software used in this project.
[ADJ+96] Malcom Atkinson, Laurent Daynes, Mick Jordan, Tony Printezis, and Susan Spence. An orthogonally persistent Java. ACM SIGMOD Record, 25(4):68--75, December 1996.
[BP93] N. S. Bowen and D. K. Pradhan. Processor- and memory-based checkpoint and rollback recovery. IEEE Computer, 26(2):22--31, February 1993.
[Chi93] Tzi-Cker Chiueh. Polar: a storage architecture for fast checkpointing. Journal of Information Science and Engineering, 9(1):61--80, March 1993.
[Cri91] Flaviu Cristian. Understanding fault-tolerant distributed systems. Communications of the ACM, 34(2):56--78, February 1991.
[Dea97] Alan Dearle. Persistent servers + ephemeral clients = user mobility. In Proceedings of the Second International Workshop on Persistence and Java, August 1997.
[DHF96] Alan Dearle, David Hulse, and Alex Farkas. Persistent operating system support for Java. In Proceedings of the First International Workshop on Persistence and Java, September 1996.
[dST96] C. Souza dos Santos and E. Theroude. Persistent Java. In Proceedings of the First International Workshop on Persistence and Java, September 1996.
[GN96] Alex Garthwaite and Scott Nettles. Transactions for Java. In Proceedings of the First International Workshop on Persistence and Java, September 1996.
[JMN+97] Maynard P. Johnson, Steven J. Munroe, John G. Nistler, James W. Stopyro, and Ashok Malhotra. Java(tm) persistence via persistent virtual storage. In Proceedings of the Second International Workshop on Persistence and Java, August 1997.
[Jor96] Mick Jordan. Early experiences with persistent Java. In Proceedings of the First International Workshop on Persistence and Java, September 1996.
[KMB98] A.-M. Kermarrec, C. Morin, and M. Banâtre. Design, implementation and evaluation of ICARE: An efficient recoverable DSM. Software - Practice and Experience, 28(9):981--1010, July 1998.
[LA90] P. A. Lee and T. Anderson. Fault Tolerance: Principles and Practice, volume 3 of Dependable Computing and Fault-Tolerant Systems. Springer Verlag, second revised edition, 1990.
[LLOW91] Charles Lamb, Gordon Landis, Jack Orenstein, and Dan Weinreb. The ObjectStore database system. Communications of the ACM, 34(10):50--63, October 1991.
[LNP90] Kai Li, Jeffrey F. Naughton, and James S. Plank. Real-time, concurrent checkpoint for parallel programs. In Proceedings of the Second ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 79--88, 1990.
[Mal96] Ashok Malhotra. Persistent Java objects: A proposal. In Proceedings of the First International Workshop on Persistence and Java, September 1996.
[MH96] J. Eliot B. Moss and Tony L. Hosking. Approaches to adding persistence to Java. In Proceedings of the First International Workshop on Persistence and Java, September 1996.
[MP97] C. Morin and I. Puaut. A survey of recoverable distributed shared virtual memory systems. IEEE Transactions on Parallel and Distributed Systems, 8(9):959--969, Sept. 1997.
[NW91] S.M. Nettles and J.M. Wing. Persistence+undoability=transactions. In Proceedings of the Twenty-Fifth Hawaii International Conference on System Sciences, pages 832--843, January 1991.
[O'B96] Patrick O'Brien. Java data management using ObjectStore and PSE. Object Design, Inc. white paper, November 1996. Available at: http://www.odi.com/content/white_papers/javawp1.html.
[PAD+97] Tony Printezis, Malcolm Atkinson, Laurent Daynes, Susan Spence, and Pete Bailey. The design of a new persistent object store for PJama. In Proceedings of the Second International Workshop on Persistence and Java, August 1997.
[PBKL95] James S. Plank, Micah Beck, Gerry Kingsley, and Kai Li. Libckpt: Transparent checkpointing under Unix. In Proceedings of the 1995 USENIX Technical Conference, pages 213--224, January 1995.
[RDH+96] J. Rosenberg, A. Dearle, D. Hulse, A. Lindstrom, and S. Norris. Operating system support for persistant and recoverable computations. Communications of the ACM, 39(9):62--69, Sept. 1996.
[RTW97] John V. E. Ridgway, Craig Thrall, and Jack C. Wileden. Toward assessing approaches to persistence for Java. In Proceedings of the Second International Workshop on Persistence and Java, August 1997.
[SA97] Susan Spence and Malcolm Atkinson. A scalable model of distribution promoting autonomy of and cooperation between PJava object stores. In Proceedings of the Thirtieth Annual Hawaii International Conference on System Sciences, pages 513--522, 1997.
[SI88] Jonathan M. Smith and John Ioannidis. Implementing remote fork() with checkpoint/restart. Technical Report CUCS-365-88, Columbia University, 1988. Available at: ftp://ftp.cs.columbia.edu/pub/reports/reports-1988/cucs-365-88.ps.gz.
[Spe96] Susan Spence. Distribution strategies for Persistent Java. In Proceedings of the First International Workshop on Persistence and Java, September 1996.
[SY85] R.E. Strom and S. Yemini. Optimistic recovery in distributed systems. ACM Transactions on Computer Systems, 3(3):204--226, Aug. 1985.
[WKMR96] Jack C. Wileden, Alan Kaplan, Geir A. Myrestrand, and John V.E. Ridgway. Our SPIN on persistent Java: The JavaSPIN approach. In Proceedings of the First International Workshop on Persistence and Java, September 1996.
[WPW+97] D. Wong, N. Paciorek, T. Walsh, J. DiCelie, M. Young, and B. Peet. Concordia: an infrastructure for collaborating mobile agents. In Proceedings of the First International Workshop on Mobile Agents, pages 86--97, 1997.
[Zwe97] M. Zweiacker. Making CORBA applications fault tolerant using checkpointing and recovery. Ada User Journal, 18(2):78--91, June 1997.
1. In Solaris 2.5. Solaris 2.6 does provide information on mapped but unallocated pages.
2. One possibility would be to use the regular javai, but provide a modified libc.so via the $LD_LIBRARY_PATH environment variable.
3. Our current recovery strategy is to open a connection to the `daytime' service, read out the date, and then substitute that nearly-dead socket for the open socket in the original process. The green_threads package discovers that the socket is now closed, and the JVM translates that condition into a java.io exception.